
TL;DR:
- AI summaries transform enterprise communication by condensing meetings, emails, and conversations into structured, accessible formats. Using hybrid extractive-abstractive and grounding techniques like RAG, they enhance decision-making but require careful prompt engineering, human review, and security measures to ensure accuracy and reliability. Building a review culture and selecting tools with grounded, multi-metric evaluation maximizes their productivity benefits while minimizing risks.
You've just wrapped a 90-minute all-hands meeting. Seventeen people attended. Three critical decisions were made, two action items assigned, and one deadline moved. By the time everyone returns to their inboxes, half the room has a different recollection of what was actually decided. This isn't a communication failure. It's a workflow failure, and it's playing out in organizations everywhere. AI-generated summaries are quietly reshaping how enterprise teams capture, distribute, and act on communication, but most managers don't realize how much the underlying technology matters for getting consistently reliable results.
Table of Contents
- What are AI summaries and how do they work?
- Methodologies and best practices for trustworthy AI summaries
- Risks, limitations, and the reality of AI-generated summaries
- Evaluating AI summary tools: Benchmarks and real-world metrics
- Practical steps: Applying AI summaries to streamline your team's workflow
- Why smart review trumps blind trust: Our take on AI summaries in 2026
- Transform your team's communication with secure AI-powered summaries
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Hybrid AI methods | The most robust AI summaries combine extraction for accuracy and abstraction for clarity. |
| Grounded outputs matter | Managers should prioritize solutions that anchor summaries in enterprise source data for compliance and reliability. |
| Review is essential | Always review AI-generated summaries to prevent inaccuracies or context loss before sharing. |
| Choose by metrics | Select tools using semantic benchmarks like BERTScore and FACTS for evidence-backed performance. |
| Real teams, real savings | Strategic use of AI summaries can truly streamline enterprise collaboration and free up valuable employee time. |
What are AI summaries and how do they work?
AI summaries are automatically generated condensations of longer content: meeting transcripts, email threads, project updates, or cross-channel conversations. Rather than manually writing recaps, teams use AI systems to extract or construct key points from raw input and deliver them in a structured, readable format.
The technology behind this falls into a few distinct categories, and understanding the difference matters for selecting the right tool.

Extractive summaries pull sentences directly from the source material. Think of it as automated highlighting. The output is accurate because it uses the original language, but it can feel choppy and miss nuance that lives between the lines.
Abstractive summaries generate new sentences that capture the meaning of the original content. This reads more naturally but opens the door to inaccuracies if the model misinterprets context.
Hybrid models combine both approaches: extracting the most critical content first, then paraphrasing it for readability. This is the dominant approach in enterprise tools today.
Retrieval-Augmented Generation (RAG) takes things further by grounding the AI's output in verified corporate data sources like internal knowledge bases, past meeting notes, or company wikis. RAG significantly reduces the risk of the model fabricating information because it's anchored to real documents. AI summaries in corporate communication use hybrid extractive-abstractive methods, detailed prompting, and grounding techniques like RAG to generate structured outputs such as executive briefs, meeting recaps, and thread summaries.
The practical output types managers see most often include:
- Meeting recaps: Action items, decisions, and discussion highlights formatted for quick review
- Executive briefs: High-level narrative summaries for leadership, stripping technical detail while keeping strategic context
- Thread overviews: Condensed views of long message chains across channels, useful for catching up after absence
- Email digests: Daily or weekly rollups of key communication threads organized by project or team
| Summary type | Primary method | Best use case |
|---|---|---|
| Meeting recap | Hybrid + speaker attribution | Post-call distribution to attendees and stakeholders |
| Executive brief | Abstractive + RAG | Board updates, cross-department leadership alignment |
| Thread overview | Extractive + chunking | Channel catch-up for remote or async teams |
| Email digest | Hybrid + filtering | End-of-day triage for high-volume inboxes |
For teams already exploring improving team productivity with AI summaries, getting this foundational understanding right is what separates tools that help from tools that create more confusion.
"The format you choose for an AI summary shapes what gets remembered and what gets missed. Picking the wrong method for the wrong context is as problematic as using no summary at all."
Methodologies and best practices for trustworthy AI summaries
With a strong grasp of AI summary types, let's explore what ensures these tools provide the specificity, transparency, and reliability needed for business decisions.
Getting reliable AI summaries is less about which model you use and more about how you structure the task you give it. Key methodologies include prompt engineering specifying persona, audience, structure, and tone; chunking for long documents; speaker attribution in meetings; and hybrid models combining extraction for factuality with abstraction for conciseness.
Here's a step-by-step workflow for turning a raw meeting transcript into a shareable, decision-ready summary:
- Define the audience before generating. A summary for a frontline team lead looks different from one going to the CFO. Configure your prompt to specify role, expected length, and tone.
- Chunk the input. For long transcripts exceeding 10,000 tokens (roughly 7,500 words), break the document into logical sections before processing. This prevents context window overflow, which causes the model to lose earlier content.
- Enable speaker attribution. Make sure your tool labels who said what. Without this, action items lose accountability and conflict resolution becomes harder.
- Specify the output structure. Use prompts that request clearly labeled sections: decisions made, open questions, action items with owners, and next steps. Free-form output makes downstream use much harder.
- Ground in verified data. Where possible, connect the AI tool to internal knowledge bases or CRM data so generated content reflects your organization's actual terminology and context.
- Apply a human review gate. Before any summary is distributed, a designated reviewer should check for missing context, misattributed statements, or factual errors.
Solid AI meeting assistant strategies always start with process design, not just tool selection.
Pro Tip: Create a library of purpose-built prompt templates for your most common meeting types: weekly standups, quarterly business reviews, client calls, and incident postmortems. Reusing structured prompts dramatically improves consistency across your team's output.
Risks, limitations, and the reality of AI-generated summaries
Even with well-engineered summaries, it's critical to understand potential edge cases and build safeguards into team processes.

AI summaries are genuinely useful, but they are not error-free. Treating them as authoritative without review is one of the most common and costly mistakes enterprise teams make. Edge cases include hallucinations (fabricated facts), context loss in long threads and meetings, missing action items, poor handling of jargon and acronyms, data silos limiting external context, and over-permissions leading to security risks.
The specific risks managers need to watch for include:
- Hallucinated content: The model generates plausible-sounding but factually incorrect information. This is more common in abstractive models and those without RAG grounding.
- Context loss: In very long meetings or threads, early content is sometimes underweighted or dropped entirely, causing key context to disappear from the summary.
- Missing action items: If the conversation doesn't use clear language like "John will send the report by Friday," the model may not recognize an implicit commitment.
- Jargon and acronym misreads: Industry-specific terminology can confuse models not fine-tuned on your organization's vocabulary, resulting in mistranslations of intent.
- Data silo limitations: If the AI tool can't access cross-platform context, such as a Jira ticket referenced in a meeting, the summary will be incomplete.
- Over-permissions: Without proper access controls, users may receive AI-generated summaries containing content from conversations they weren't authorized to see.
"Grounded enterprise RAG is preferred over ungrounded generative AI, particularly in regulated industries where factual accuracy and audit trails are non-negotiable requirements."
AI is transforming corporate communications, but it also risks inaccuracies requiring review. Grounded enterprise RAG is preferred over ungrounded generative AI, and local models are cheaper but hallucinate more than cloud-based alternatives.
Every organization using AI summaries needs a documented review workflow: who reviews, what they check, how errors are flagged, and what the escalation path is. This isn't bureaucracy. It's the foundation of trustworthy enterprise communication. Building secure AI communication best practices and addressing security in AI summaries should be part of every rollout plan.
Evaluating AI summary tools: Benchmarks and real-world metrics
Understanding the risks is the first step. Next, managers need clear criteria to navigate the crowded AI tool landscape.
Choosing an AI summary tool based on vendor marketing alone is a trap. You need objective metrics to compare performance, especially for high-stakes communication like compliance reviews, board reporting, or cross-functional project tracking.
Traditional evaluation relied on ROUGE scores, which measure word overlap between a generated summary and a human-written reference. The problem? High ROUGE scores don't guarantee the summary is actually meaningful or factually correct. A model can repeat key phrases without capturing what actually mattered.
Newer, more reliable metrics include:
- BERTScore: Uses contextual embeddings to measure semantic similarity rather than word overlap, giving a better picture of whether the meaning was preserved.
- MoverScore: Weighs the semantic distance between generated and reference text using word movement, capturing fluency and meaning together.
- FACTS Grounding: A benchmark specifically designed for long-form factuality, testing whether AI-generated content is anchored in verifiable source material rather than inferred or fabricated.
Empirical benchmarks shift from ROUGE to semantic metrics like BERTScore and MoverScore. Multi-dimensional evaluations show Claude excels in human-like quality while DeepSeek leads in factual consistency. FACTS Grounding is the benchmark for long-form factuality.
Factual consistency peaks at short summary lengths around 50 tokens, while overall quality peaks at longer outputs. Use benchmarks like FACTS for vendor selection in high-stakes communications.
| Model | Benchmark strength | Key advantage | Best suited for |
|---|---|---|---|
| Claude | Human-quality evals | Natural, readable output | Executive briefs, client-facing comms |
| DeepSeek | FACTS Grounding | Factual consistency | Compliance, regulated industry use |
| GPT-4o | BERTScore + MoverScore | Balanced semantic accuracy | Cross-functional recaps, thread summaries |
| Fine-tuned local models | Domain-specific tasks | Low latency, cost-efficient | Routine internal recaps with human review |
When evaluating AI collaboration tools for summary quality, never rely on a single benchmark. Ask vendors for multi-metric evaluation results specific to your industry's communication patterns. For more depth on enterprise AI tool benchmarks, review results across multiple independent evaluation frameworks before committing.
Pro Tip: Request sample summaries from vendors using your actual meeting transcripts or anonymized conversation threads. Real performance on your content is far more predictive than lab benchmarks on generic datasets.
Practical steps: Applying AI summaries to streamline your team's workflow
With the metrics and risks in hand, you're ready to apply AI summaries to real scenarios. Here's a step-by-step approach for turning strategy into action.
The biggest obstacle to successful AI summary adoption isn't technology. It's the absence of a structured deployment plan. Organizations that pilot without process design often abandon tools that would have worked with proper setup.
- Assess your summary needs. Identify the top three communication bottlenecks in your team's workflow. Are meeting recaps late? Are action items falling through? Is leadership missing key project updates? This scopes your deployment focus.
- Shortlist tools against your criteria. Use the benchmarks above and filter by security, compliance support, integration with your existing stack, and grounding capability.
- Run a structured pilot. Deploy the tool with one team for four to six weeks. Define what "success" looks like upfront: faster recap turnaround, reduced follow-up emails, or improved action item completion rates.
- Set up a review workflow. Designate a reviewer for each summary type. Create a shared feedback channel where reviewers flag errors or missing context, and use that input to refine your prompt templates.
- Measure results against baseline. Track time saved on manual recaps, error rates caught in review, and qualitative feedback from summary consumers. Iterate based on real data.
When vetting vendors, prioritize tools with enterprise grounding capabilities, hybrid processing methods, and verifiable output trails to enhance collaboration while ensuring compliance and accuracy.
Key vendor questions to add to your checklist:
- What grounding method does the tool use, and can it connect to our internal knowledge base?
- How does the tool handle data residency and compliance requirements?
- Can we audit which source content contributed to a given summary?
- Does the tool support role-based output customization?
Understanding AI in modern team communication and following proven enterprise AI communication strategies will help your team move from pilot to full deployment with confidence.
Pro Tip: Involve reviewers from cross-functional teams during the pilot phase, not just the team deploying the tool. Different functions catch different types of errors, and broader input accelerates prompt refinement considerably.
Why smart review trumps blind trust: Our take on AI summaries in 2026
The practical steps above empower immediate results, but there's a broader point that the industry keeps sidestepping, and we think it's the most important one.
Most organizations that struggle with AI summaries aren't failing because they picked the wrong model. They're failing because they assumed the technology would do the organizational work for them. It won't. A model can surface key points with impressive precision, but it has no understanding of your organizational politics, your team's unspoken commitments, or the subtle signals that a decision was contested even if the language of the transcript was civil.
The real opportunity in 2026 isn't finding a better model. It's building a review culture that treats AI summaries as a first draft, not a finished product. The teams that get the most value from these tools are the ones where reviewers have genuine authority to correct, expand, and push back on AI output before it circulates.
There's also a systems-level issue the industry underestimates: orchestration. Managers who think carefully about evolving team communication trends recognize that the next competitive advantage won't come from choosing Claude over GPT or RAG over extractive models. It will come from organizations that build deliberate human-AI feedback loops, where reviewer corrections actively improve the system over time.
Blind trust in AI output is the fastest way to erode your team's trust in the process itself. But rigid skepticism that ignores genuine efficiency gains leaves real value on the table. The productive middle ground is a review culture: structured, accountable, and continuously improving.
Transform your team's communication with secure AI-powered summaries
Reimagining how your team handles communication starts with the right infrastructure behind it. Luxenger brings AI-powered summaries directly into your enterprise messaging environment, turning lengthy conversations, meetings, and threads into clear, structured, decision-ready recaps without sacrificing security or compliance.
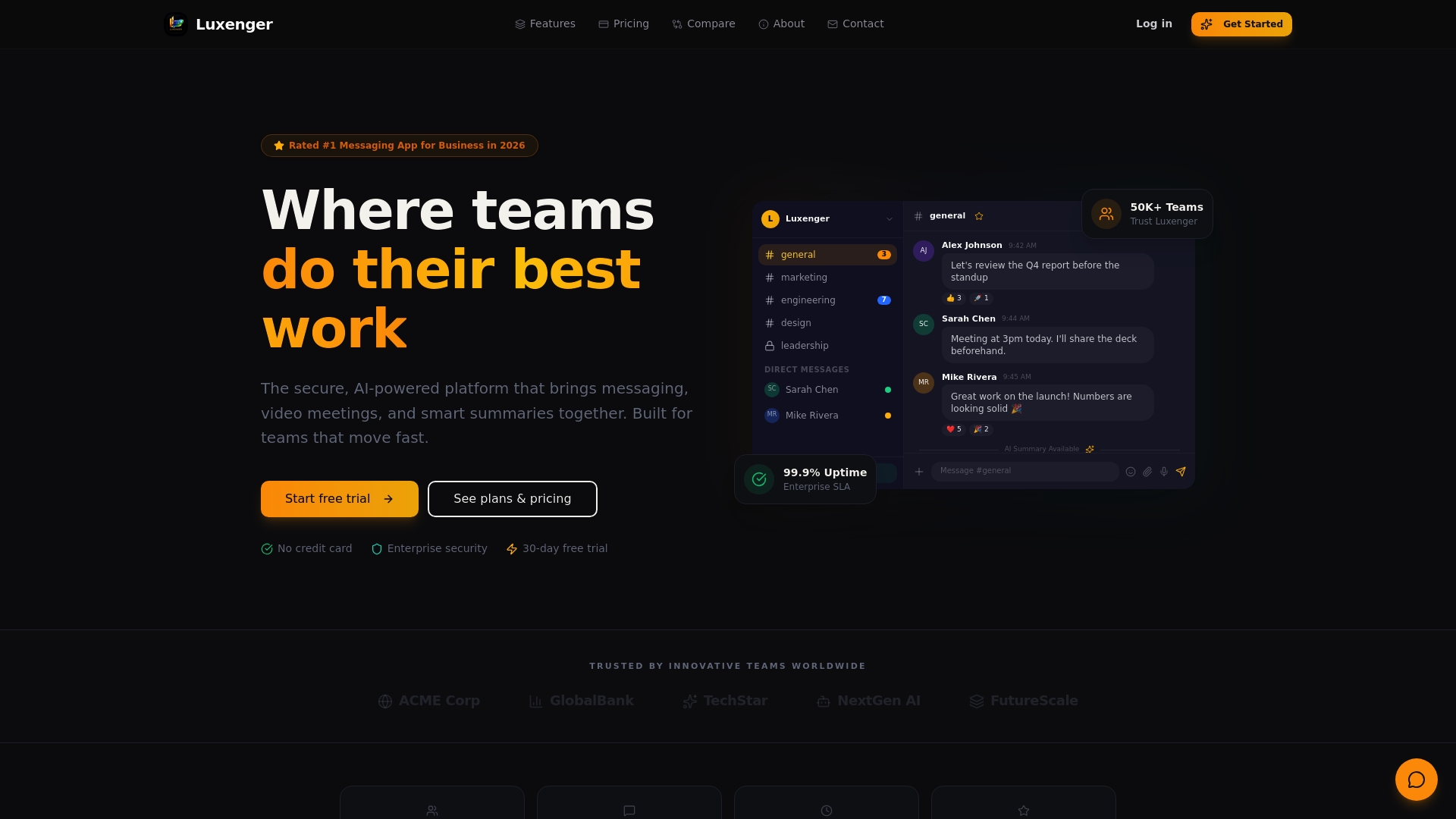
Luxenger is built for organizations that need more than convenience. Its enterprise operations platform combines bank-grade security with hybrid AI summarization, real-time translation, and voice huddles, all integrated into a single communication layer your teams already use. There's no trade-off between power and protection. You can explore plans and deployment options at Luxenger pricing to find the right fit for your organization's scale and requirements. Book a demo and see how teams are already using Luxenger to close the gap between what gets said and what gets done.
Frequently asked questions
What are the main types of AI summaries used in enterprises?
The most common are meeting recaps, executive briefs, and threaded conversation overviews. These typically use hybrid extractive-abstractive methods combined with grounding techniques like RAG to produce reliable, structured output.
How can managers improve the accuracy of AI summaries?
By customizing prompts for audience and context, applying chunking for long documents, and reviewing outputs with subject experts. Prompt engineering that specifies persona, structure, and tone is one of the most effective accuracy levers available.
What risks do AI summaries present for enterprise teams?
Risks include hallucinated facts, context loss, missing action items, compliance issues, and data security gaps. Over-permissions and data silos are particularly serious concerns in regulated environments.
What metrics should buyers look for when selecting an AI summary tool?
Look for semantic metrics like BERTScore and MoverScore rather than ROUGE scores alone. The FACTS Grounding benchmark is especially important for high-stakes communications where long-form factuality is non-negotiable.
How do AI summaries impact team productivity and collaboration?
They reduce manual recap effort, increase meeting clarity, and streamline access to key decisions across teams. However, AI efficiency gains come with inaccuracy risks, which makes a structured human review process essential for sustained value.