
TL;DR:
- A real-time translation workflow connects speech recognition, machine translation, and output delivery to facilitate seamless multilingual communication with minimal delay. It is essential for distributed teams to eliminate delays, improve decision speed, and enhance inclusivity in global collaboration. Building phased implementations with human oversight, proper infrastructure, and continuous feedback ensures accuracy, trust, and effective deployment at enterprise scale.
A real-time translation workflow is the end-to-end system of tools, APIs, and processes that converts spoken or written content from one language to another with minimal delay, enabling distributed teams to communicate across language barriers without interrupting the flow of work. The industry term for the underlying technology is live language processing, and it now powers everything from multilingual support calls to global all-hands meetings. Platforms like Tencent RTC, Translated, and Wordly have pushed this technology into enterprise-grade territory, with AI interpretation systems now supporting 54 languages at sub-1-second latency. For any organization running distributed teams across multiple regions, getting this workflow right is no longer optional.
What is a real-time translation workflow and why does it matter?
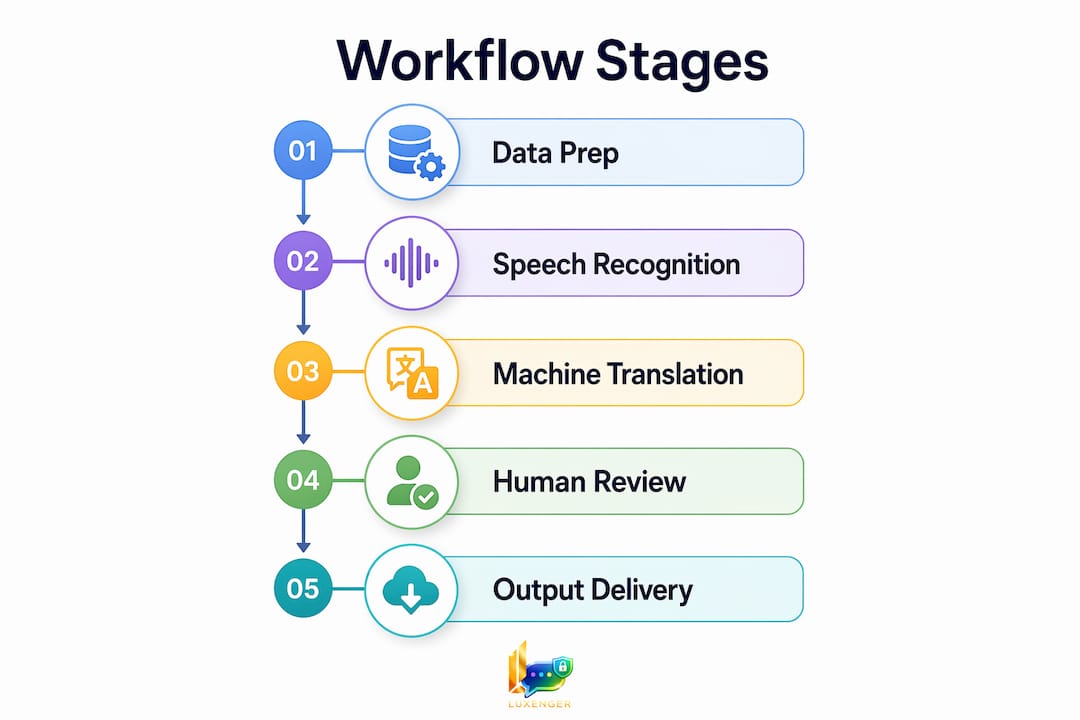
A real-time translation workflow connects three core processes: speech recognition, machine translation, and output delivery, either as text or synthesized speech. Each stage must hand off to the next in milliseconds for the system to feel natural. When any stage lags, the entire conversation breaks down.

The business case is direct. Distributed teams that rely on asynchronous translation lose hours to delayed decisions, misread tone, and cultural misinterpretation. A live language processing workflow eliminates that gap. It lets a product manager in São Paulo and an engineer in Seoul participate in the same standup without a human interpreter on retainer.
The role of real-time translation has expanded significantly in 2026 because hybrid human-AI models have matured. Pure machine translation struggled with domain-specific jargon and cultural nuance. Today's best workflows combine AI speed with human oversight, a model that industry leaders recommend for any deployment where accuracy and cultural context both matter. The advantages of real-time translation at this level go beyond convenience. They include measurable cost savings on interpretation services, faster decision cycles, and stronger inclusion for non-native speakers on global teams.
What prerequisites and tools are needed before you build?
Before writing a single line of API configuration, you need to audit your infrastructure and data assets. Skipping this step is the most common reason translation workflows fail in the first month.
Hardware and software requirements:
- Automatic Speech Recognition (ASR): The entry point for any spoken workflow. Cloud-based ASR from providers like Google, Microsoft Azure, or AWS Transcribe handles most enterprise use cases.
- Neural Machine Translation (NMT) engine: The core translation layer. Options range from open APIs to specialized engines like Translated's Lara, which is trained on domain-specific corpora.
- Text-to-speech (TTS) or speech-to-speech output: Choose based on use case. Customer support calls need TTS. Text-based meeting captions need only a display layer.
- Low-latency network infrastructure: Sub-3-second latency is the target for maintaining conversational flow. Edge computing nodes reduce round-trip time for geographically dispersed teams.
- Translation memory and glossaries: Pre-loaded terminology databases prevent the engine from mistranslating product names, legal terms, or internal acronyms.
Data preparation is non-negotiable. Import your company glossary before any pilot. A translation engine that renders your product name incorrectly in front of a client destroys trust faster than a language barrier ever would.
Pro Tip: Use pre-opening session management in your streaming architecture. Systems built with this approach achieve a 98% reliability pass rate in extended soak tests, compared to 65% with basic reconnection methods alone.
The human-in-the-loop component is not a luxury for critical workflows. A bilingual reviewer monitoring live output can catch intent errors that no AI model currently handles reliably, particularly in negotiations, legal discussions, or sensitive HR conversations.
How to set up and integrate a real-time translation workflow step by step
A phased rollout focused on measurable ROI use cases is the proven approach. Starting with a high-volume, low-risk use case like multilingual customer support gives you clean performance data before you scale to executive meetings or live events.
-
Define your pilot use case. Multilingual support calls are the ideal starting point. They are high-frequency, well-documented, and produce clear quality metrics like resolution time and customer satisfaction scores.
-
Prepare your data assets. Import domain glossaries and translation memories into your NMT engine. If you use Translated Lara or a similar adaptive engine, feed it historical transcripts from your specific industry to accelerate accuracy.
-
Integrate APIs into your existing platforms. Pre-built connectors for CRM systems, video conferencing tools, and messaging platforms cut integration time significantly. Map your data flow before touching any configuration: audio in, ASR out, NMT in, translated text or audio out.
-
Configure audio chunk sizing carefully. Streaming audio in approximately 300ms chunks balances latency and accuracy effectively. Smaller chunks reduce delay but increase transcription errors. Larger chunks improve accuracy but push latency past the conversational threshold.
-
Conduct user acceptance testing with real end-users. UAT with customer support agents and bilingual staff is mandatory before broad deployment. They will surface usability problems that engineers miss entirely, including display timing, font legibility in non-Latin scripts, and speaker attribution in multi-person calls.
-
Deploy with monitoring and feedback loops. Capture every correction a human reviewer makes. Feed those corrections back into your NMT model. Continuous retraining through this feedback loop reduces editing time and improves accuracy with each iteration.
Pro Tip: Build escalation protocols into your workflow from day one. When the AI confidence score drops below a defined threshold, the system should flag the segment for human review rather than displaying a low-quality translation to the end-user.
For teams building on existing remote team workflows, the translation layer integrates most cleanly when it sits at the platform level rather than as a bolt-on browser extension.
What are the common challenges and how do you overcome them?
Even well-architected workflows hit predictable friction points. Knowing them in advance lets you build mitigations before they become incidents.
Latency and cognitive load are the most misunderstood challenge. The problem is not just technical delay. Sub-second streaming creates cognitive dissonance because partial translations appear before sentences complete, forcing listeners to mentally reconstruct meaning in real time. The fix is to time display output to natural sentence boundaries, not raw ASR output. This adds a small buffer but dramatically improves comprehension.
Domain jargon and intent preservation require ongoing attention. In live meeting translation, preserving the speaker's intent matters more than literal word-for-word accuracy. A phrase like "let's table this" means opposite things in American and British English. Your glossary and human reviewer together catch these before they cause decisions to go sideways.
Multi-speaker overlap degrades ASR accuracy sharply. Most enterprise ASR engines handle single-speaker audio well but struggle when two participants speak simultaneously. Mitigation strategies include:
- Speaker diarization models that separate audio streams by voice signature
- Meeting facilitation protocols that reduce crosstalk (muting by default, hand-raise queues)
- Fallback display that flags overlapping segments rather than guessing at content
Data privacy and compliance cannot be an afterthought. Audio streams passing through cloud-based translation APIs may contain personally identifiable information, financial data, or attorney-client privileged content. Verify that your chosen provider offers data residency options, end-to-end encryption, and contractual data processing agreements aligned with GDPR, HIPAA, or whichever frameworks govern your industry.
The most overlooked risk in any live translation deployment is not accuracy. It is the moment a participant realizes the system mistranslated something sensitive and loses trust in every output that follows. Build human oversight into the workflow before that moment arrives.
How do different real-time translation approaches compare?
Choosing the right architecture depends on your use case, budget, and tolerance for latency versus accuracy trade-offs.
| Approach | Latency | Accuracy | Cost | Best for |
|---|---|---|---|---|
| Cascaded pipeline (ASR + NMT + TTS) | 1 to 3 seconds | High with tuning | Moderate | Customer support, webinars |
| End-to-end speech-to-speech | Under 1 second | Moderate, improving | Higher | Live events, executive meetings |
| Human-in-the-loop hybrid | 2 to 5 seconds | Highest | Highest | Legal, medical, negotiations |
| AI-only automated | Under 1 second | Variable by domain | Lowest | Internal async updates, chat |
The cascaded pipeline remains the enterprise default in 2026 because each component is independently auditable and replaceable. If your ASR engine underperforms in a specific accent, you swap it without rebuilding the entire workflow.
End-to-end speech-to-speech models, like those built on Google's Gemini Live API, are closing the accuracy gap fast. The Gemini Live architecture demonstrates that sub-second voice translation with acceptable accuracy is achievable for general business conversation, though domain-specific deployments still benefit from the cascaded approach with custom NMT tuning.
For webinars and large-scale live events, the instant translation process needs to prioritize display timing over raw speed. Attendees reading captions tolerate a two-second delay far better than they tolerate fragmented partial sentences appearing mid-thought. For customer support, the opposite is true: speed matters more because the caller is waiting for a response.
Emerging trends worth tracking include AR-based translation overlays for in-person multilingual meetings and multi-modal translation that handles shared documents and screen content alongside spoken audio. Neither is production-ready for most enterprises in 2026, but both will reshape the future of AI-powered team communication within the next two years.
Key takeaways
A successful real-time translation workflow requires layered architecture, phased deployment, and continuous human oversight to deliver accuracy and trust at enterprise scale.
| Point | Details |
|---|---|
| Start with a pilot use case | Multilingual support calls deliver clean ROI data before you scale to higher-stakes meetings. |
| Tune audio chunk sizing | Approximately 300ms chunks balance latency and accuracy; adjust based on your network and use case. |
| Time output to sentence boundaries | Displaying translations at natural pauses reduces cognitive load and improves comprehension. |
| Build human oversight in from day one | Human-in-the-loop review catches intent errors and cultural nuance that AI models still miss. |
| Feed corrections back into the model | Continuous retraining through a feedback loop improves accuracy and reduces editing time over time. |
Where the industry is heading, and what I'd do differently
I have watched organizations spend months configuring technically impressive translation pipelines, only to deploy them without a single bilingual end-user in the testing room. The result is always the same: the system works in demos and fails in production because nobody accounted for how people actually speak in meetings. They interrupt each other. They use shorthand. They reference context from three conversations ago.
The hybrid AI-human model is not a compromise. It is the correct architecture for any workflow where the cost of a mistranslation exceeds the cost of a human reviewer. That threshold is lower than most technology teams assume. One mistranslated contract clause or one misread tone in a sensitive HR conversation can cost more than a year of human oversight.
What I would advocate for in any 2026 deployment is building the feedback loop before the pilot ends, not after. Every correction a human reviewer makes is a training signal. Organizations that capture those signals from week one end up with a model that is materially more accurate by month three. Organizations that add the feedback loop later are essentially starting over.
The future direction is clear: sub-500ms latency across 100-plus languages, tighter integration with AI communication tools at the platform level, and multi-modal translation that handles the full context of a meeting, not just the audio stream. The organizations that will benefit most are those that treat translation not as a feature to activate but as a workflow to design, test, and continuously improve.
— Matthew
How Luxenger supports multilingual teams at enterprise scale
Luxenger is built for organizations that cannot afford communication gaps across languages or time zones. The platform's built-in real-time translation works directly inside the messaging and voice huddle environment, so your teams do not need to switch tools or manage separate translation APIs. Every message and conversation stays protected under bank-grade security standards, which matters when your multilingual discussions involve financial data, client information, or proprietary strategy. For enterprises managing distributed teams across multiple regions, Luxenger's enterprise messaging platform provides the secure, scalable foundation that makes a live language processing workflow practical from day one rather than a multi-month integration project.
FAQ
What is a real-time translation workflow?
A real-time translation workflow is the connected system of speech recognition, machine translation, and output delivery that converts spoken or written content between languages with minimal delay. It enables multilingual teams to communicate live without waiting for post-meeting translations.
How much latency is acceptable in a live translation system?
Sub-3-second latency is the accepted upper limit for maintaining conversational flow in business settings. Above 3 seconds, participant comprehension and engagement drop sharply.
What is the difference between cascaded pipeline and end-to-end speech translation?
A cascaded pipeline runs audio through separate ASR, NMT, and TTS components in sequence, offering high accuracy and modularity. End-to-end speech-to-speech models process audio in a single pass, delivering lower latency but less control over individual components.
Why is human-in-the-loop review still necessary with advanced AI translation?
AI models still miss cultural nuance, domain-specific intent, and context-dependent meaning that human reviewers catch reliably. For legal, medical, or high-stakes business conversations, hybrid human-AI models remain the industry standard for accuracy.
How do you improve translation accuracy over time?
Capture every human correction made during live review and feed those corrections back into your NMT model. This continuous retraining loop reduces errors progressively and is the most cost-effective path to long-term accuracy improvement.